📄 Paper · 💻 Code · 📝 OpenReview
Zeyuan Liu¹*, Jeonghye Kim¹˒²*, Xufang Luo¹†, Dongsheng Li¹, Yuqing Yang¹
Microsoft Research¹ · KAIST² · ICLR 2026
* Equal contribution; work done during an internship at Microsoft Research | † Corresponding author

Existing LLM-based agents rely heavily on prior knowledge and thus fail to learn effectively in environments that require discovering and exploring novel states. To address this limitation, we propose a reinforcement learning framework that promotes exploration through memory and combines on- and off-policy optimization to improve generalization without relying on memory at inference time.
Abstract
Exploration remains the key bottleneck for large language model agents trained with reinforcement learning. While prior methods exploit pretrained knowledge, they fail in environments requiring the discovery of novel states. We propose Exploratory Memory-Augmented On- and Off-Policy Optimization (EMPO²), a hybrid RL framework that leverages memory for exploration and combines on- and off-policy updates to make LLMs perform well with memory while also ensuring robustness without it. On ScienceWorld and WebShop, EMPO² achieves 128.6% and 11.3% improvements over GRPO, respectively. Moreover, in out-of-distribution tests, EMPO² demonstrates superior adaptability to new tasks, requiring only a few trials with memory and no parameter updates. These results highlight EMPO² as a promising framework for building more exploratory and generalizable LLM-based agents.
1. Key Results
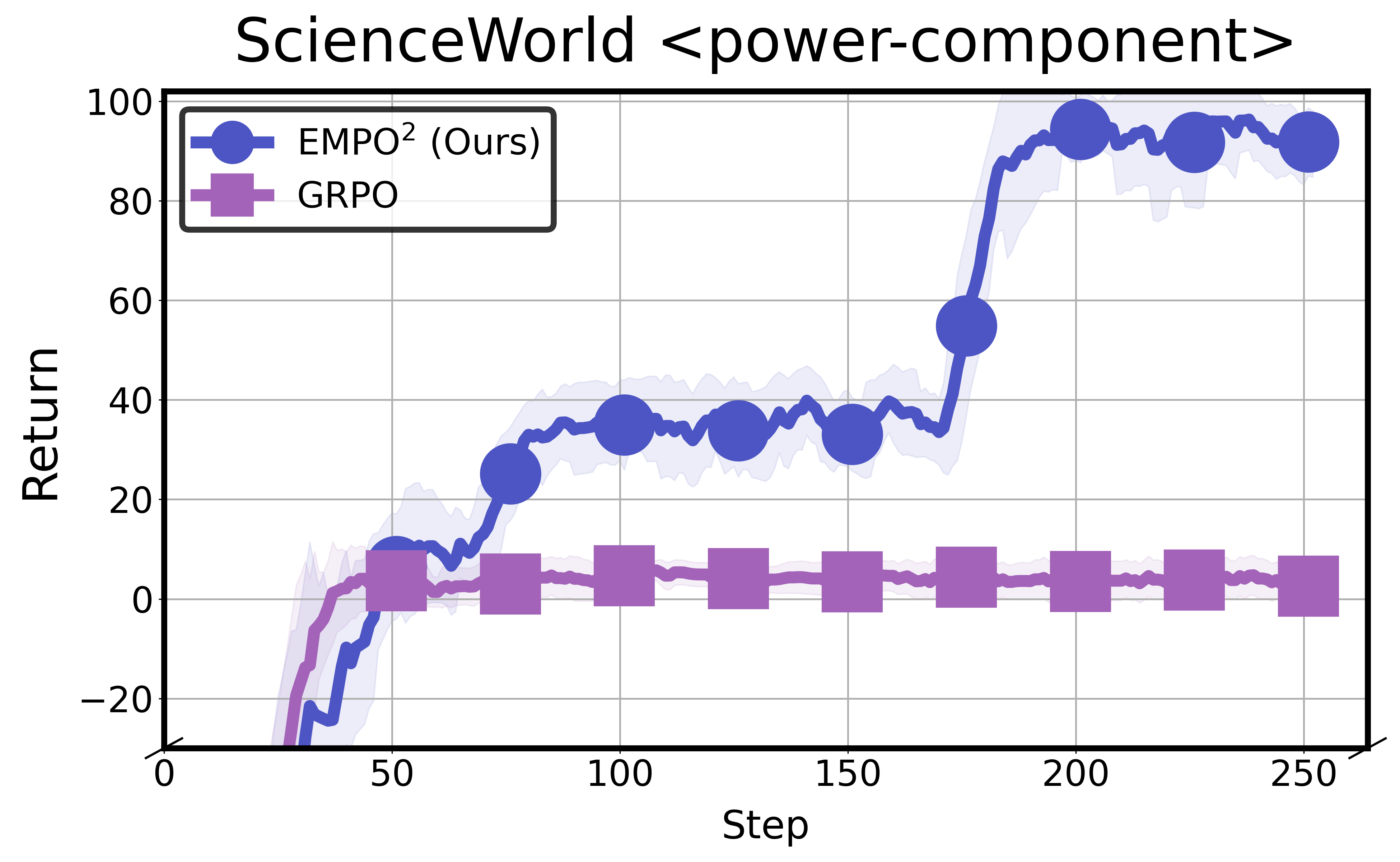
(a) Comparison of the learning curves of GRPO and EMPO² (ours) on the ScienceWorld power-component task. While GRPO converges to suboptimal performance, EMPO² continues to improve and accomplish the task.
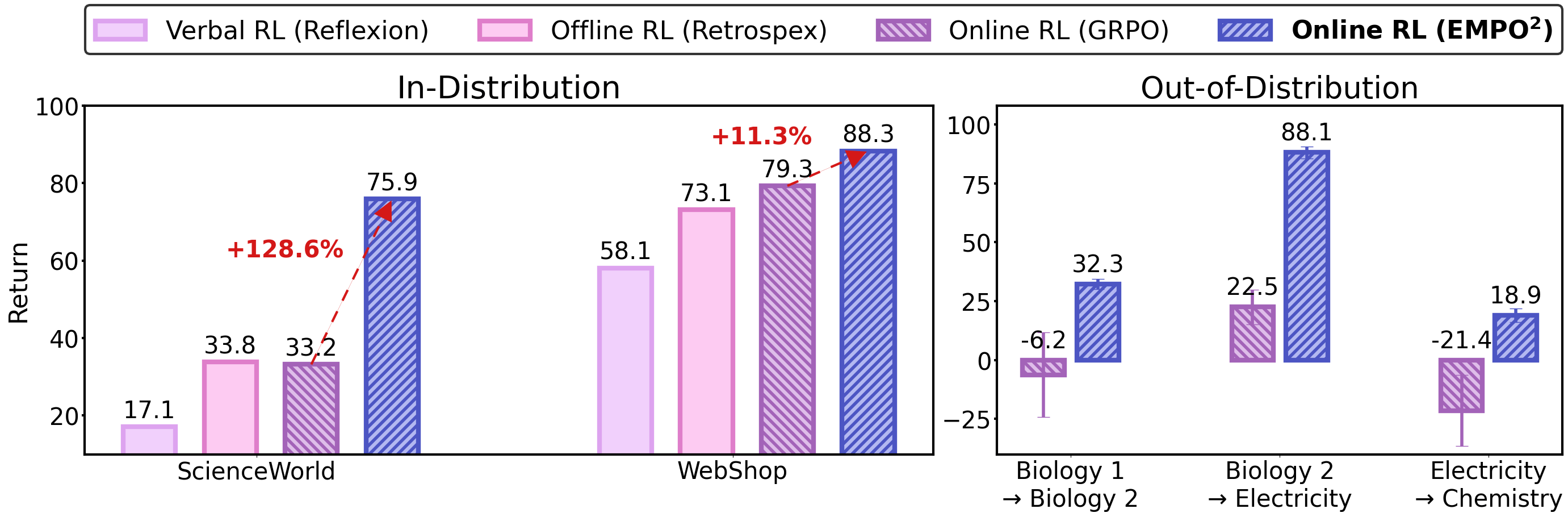
(b) Comparison of EMPO² and other baselines in in-distribution (ID) and out-of-distribution (OOD) settings on ScienceWorld and WebShop. In ID experiments, it adapts well to familiar environments, achieving 128.6% on ScienceWorld and 11.3% on WebShop improvements over GRPO. In OOD experiments, it also shows strong performance with few trials and no weight updates, indicating effective use of memory to explore unfamiliar environments.
2. The Exploration Problem of LLM Agents
Although LLMs possess strong prior knowledge, it often misaligns with environment rules, requiring exploration and trial-and-error adaptation. However, LLM agents struggle to explore beyond their confident behavior distribution.
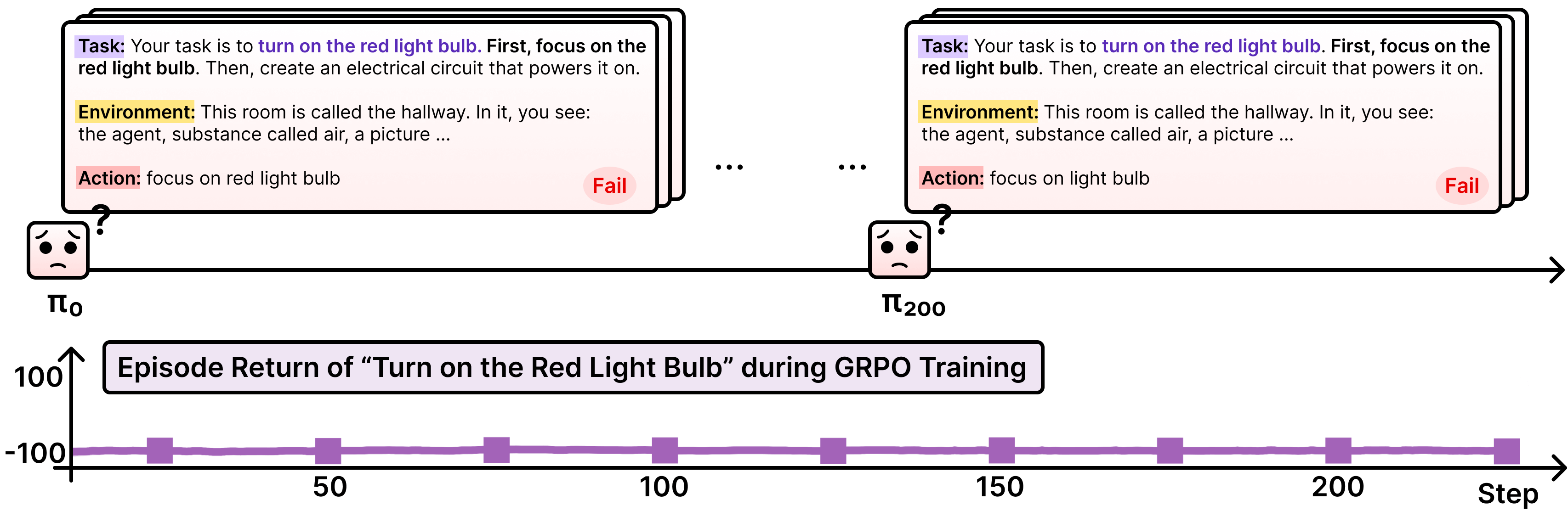
When training an LLM with GRPO in ScienceWorld, limited exploration leads to failure. For example, in the task “turn on the red light bulb,” the agent fails to find the bulb and keeps repeating the same actions, resulting in stagnant performance despite additional training.
We study online RL for training agents without prior knowledge of environment rules, where the main challenge is insufficient exploration. Agents often follow instructions literally instead of searching the environment, and methods like GRPO, which rely on scalar rewards, further restrict exploration and learning.
3. Advancing Exploration with Self-Generated Memory
EMPO² leverages memory to maintain continuity across rollouts. In addition to learning through policy optimization, the agent reviews past rollouts to generate self-guidance (tips) stored in memory, which conditions future rollouts and promotes exploration. By exploiting the pretrained LLM’s summarization and reflection abilities as auxiliary signals beyond scalar rewards, EMPO² enables autonomous exploration that is later consolidated through policy updates.
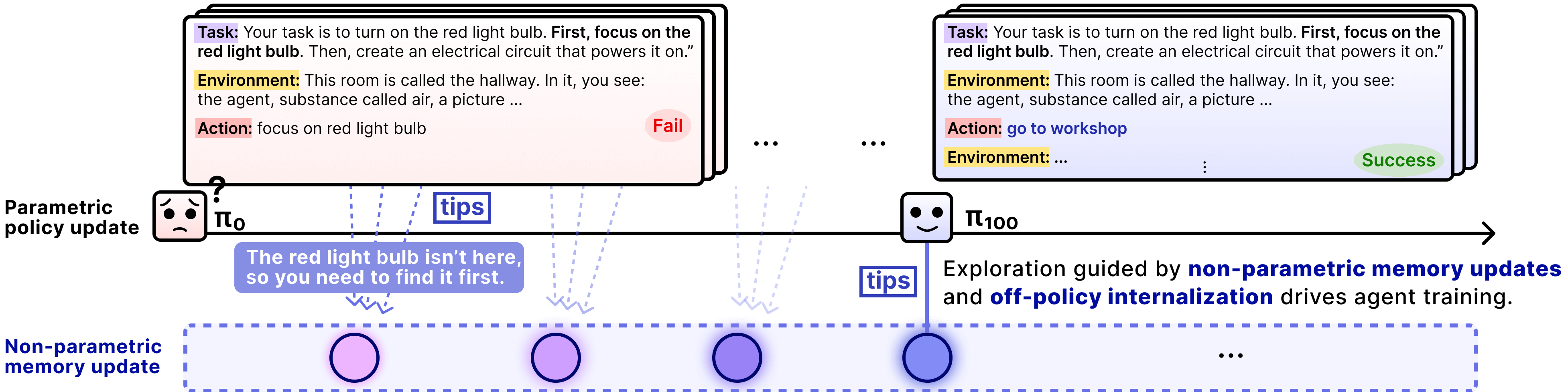
4. Parameterizing Non-Parametric Updates via Hybrid Policy Optimization
EMPO² introduces hybrid learning that combines memory-assisted exploration with parameter learning. The agent alternates between standard rollouts and memory-augmented rollouts, where retrieved tips from past experiences condition action generation and encourage exploration. While trajectories without memory are updated on-policy, memory-augmented trajectories are updated either on-policy or off-policy.
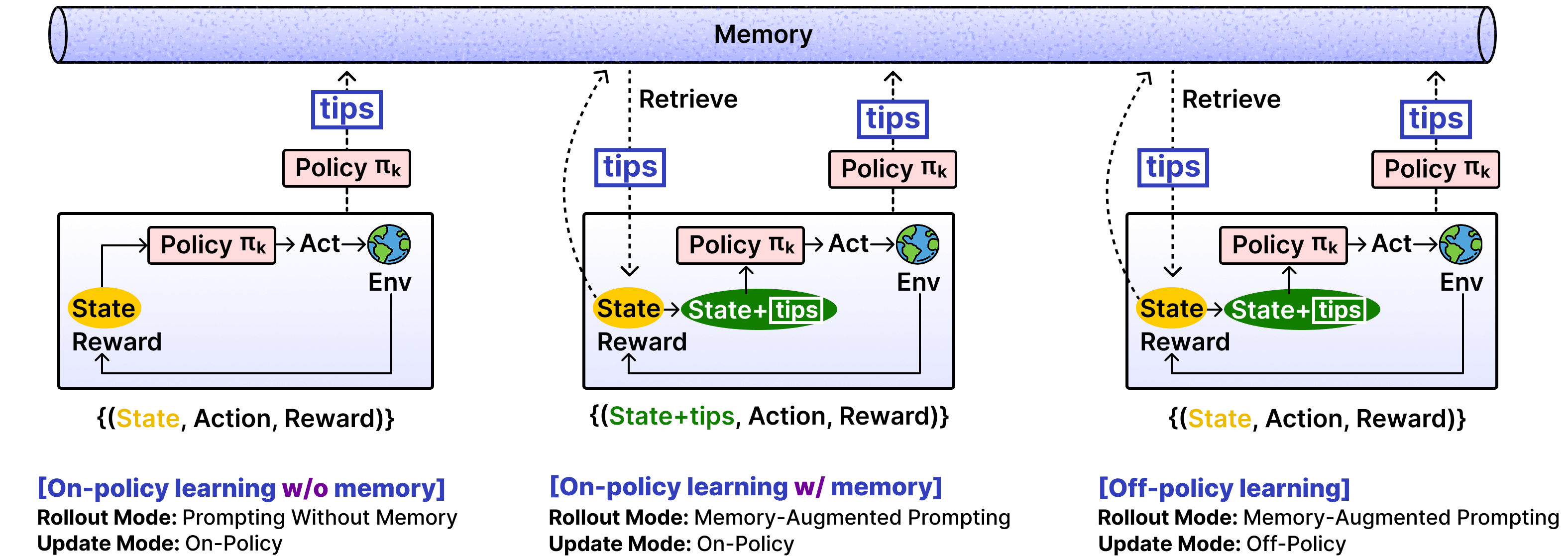
In the off-policy case, the agent performs reward-guided self-distillation, where high-reward behaviors discovered under tip-conditioned rollouts are selectively distilled into the base policy that conditions only on the state and task. Memory thus serves as temporary scaffolding for exploration, while its benefits are internalized into the model parameters, removing the need for memory at inference time.
5. Results
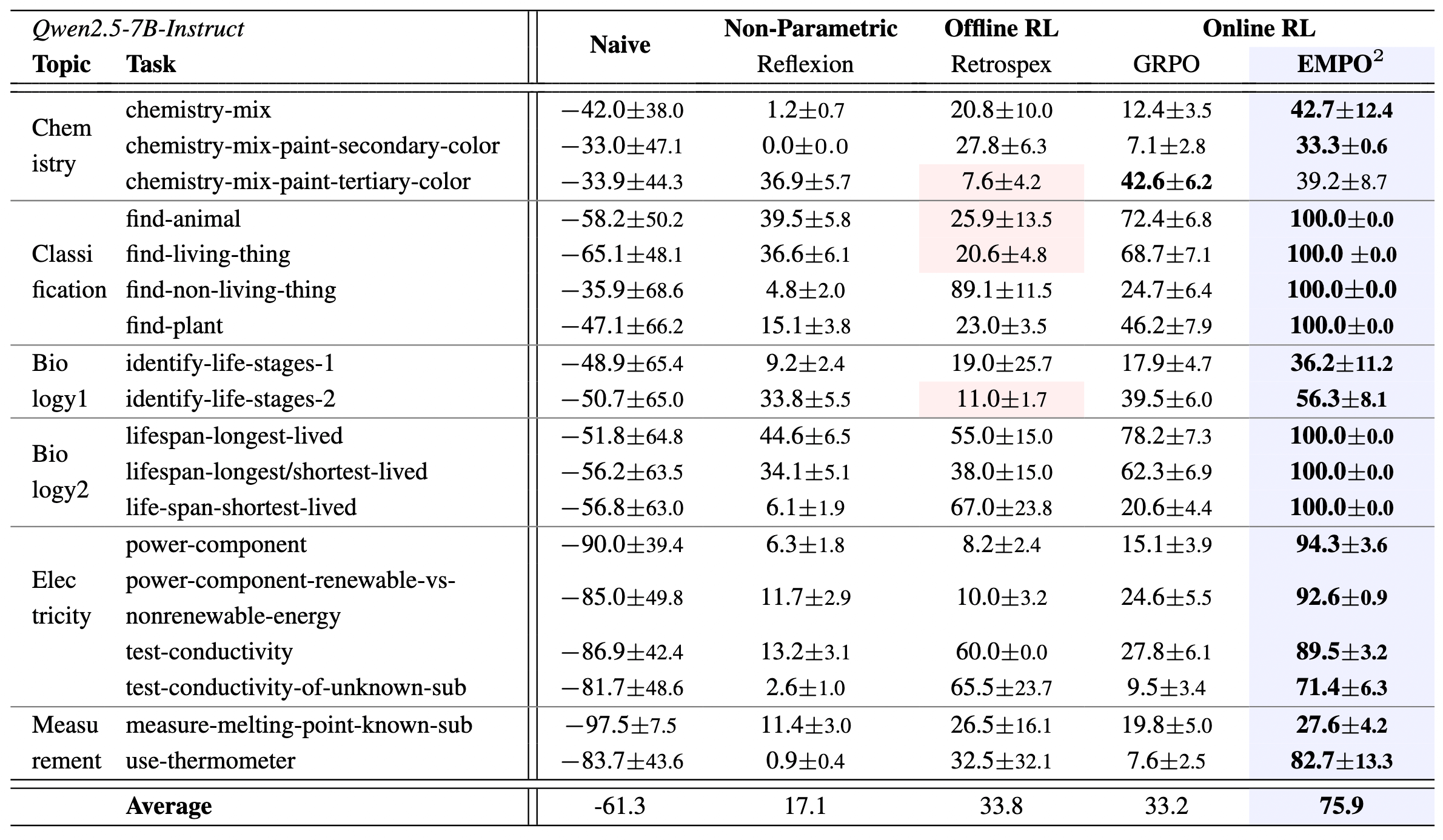
(a) Comparison results of ScienceWorld. Each task in ScienceWorld contains multiple variants. Bold shows the best performance per task, while red shading marks cases where parametric updates score lower than non-parametric updates.

(b) Comparison results of WebShop. We average results over three random seeds and report both the mean score and the mean success rate.

(c) Adaptation to new tasks. With memory enabled, EMPO² adapts rapidly to novel tasks, yielding an average improvement of 136% within 10 steps. GRPO shows greater variability and often fails to adapt to unfamiliar tasks.
BibTeX
| |